Video#
Intro#
Xin chào các bạn. Chop trở lại với một video mới. Video lần này là về lập trình Rust.
Trong lập trình có một mảng khá là hay mà chắc ai lập trình nhiều cũng phải đụng tới là lập trình Concurrency. Tạm dịch là lập trình chạy độc lập ha, wiki thì nó dịch là lập trình tương tranh nhưng mà nghe thấy lạ tai quá, Mình sẽ dùng từ chuyên ngành là lập trình Concurrency hay Lập trình chạy độc lập cho dễ.
Thì các hệ thống bây giờ thường tổ chức theo dạng chạy độc lập. Các bộ phận không lệ thuộc vào nhau kiểu nối tiếp dây chuyền để vận hành mà được tổ chức theo dạng hợp xướng, phối hợp với nhau như một dàn nhạc - hay còn gọi là orchestrate.
Hệ thống kiểu như Kubernetes là một dạng như vậy. Là một hệ thống distributed system xử lý tác vụ ở dạng phân tán công việc ra. Mỗi node sẽ xử lý riêng biệt các tác vụ được giao cho nó.
Còn về lập trình lên 1 chương trình máy tính thì nếu các bạn xem biểu đồ của tốc độ CPU sẽ thấy nó không còn đi lên về tốc độ nữa mà chuyển sang hướng xử lý bằng nhiều core. Không những nhiều core mà còn chuyên biệt hoá các core nữa, như gần đây Apple có ra CPU có core tối ưu tiết kiệm năng lượng, hay Google có core tensor để tối ưu xử lý AI, v.v
Nên việc học để lập trình xử lý song song nhiều tác vụ là một mảng không thể thiếu nếu các bạn thực sự nghiên cứu về lập trình.
Và cá nhân mình cảm thấy rất thú vị khi tìm hiểu thêm về mảng này. Mặc dù đụng tới nó không nhiều trong công việc hằng ngày nhưng mà khi cần cũng là một công cụ không thể thiếu trong bộ đồ nghề.
Ví dụ thì như vừa rồi mình có thực hiện một chương trình tính block scheduler cho blockchain Cardano. Chương trình có 1 cái bottleneck là thực hiện việc tính toán các block theo kiểu tuần tự.
Nên việc tính toán chỉ sử dụng 1 core CPU thôi. Thì mình hiện có tham gia cải tiến và kết quả áp dụng concurrency thì giảm thời gian tính toán xuống còn 1/5.
Bạn nào quan tâm thì có thể vào github của mình để xem chương trình. Chương trình này thì mình viết bằng Haskell cũng lâu rồi. Link ở trong description ha.
Thì cái ví dụ của project bên blockchain Cardano hơi phức tạp, trong video này thì mình sẽ lấy ví dụ với Bitcoin sẽ dễ hơn.
Đối với Bitcoin thì một trong những cơ chế vận hành của nó là Mining.
Thì mô tả sơ Mining: là tìm ra một cái con số nonce sao cho hash con số này với nội dung của cái block thì sẽ tạo ra một chuỗi hash bắt đầu bằng nhiều số 0 nhất.
OK thì để demo luôn, ví dụ chúng ta có 1 block như vầy ha. Nội dung đơn giản thôi. Block number 123. Nội dung của block thì như sau:
Có previous hash nè. Có transaction ví dụ: Alice transfers cho Bob 5 đồng, Bob transfer cho Chop 10 đồng. v.v
Thì nếu chúng ta hash block này với Nonce 0. Dùng hàm hash_block này đây.
Xem sơ hàm hash_block. Thì để không làm phức tạp quá cho việc demo, mình sẽ ví dụ đơn giản thôi là concat cái nonce ở dạng string và content của block ở dạng string lại thôi ha, với spec của từng blockchain thì format hashing sẽ khác nhau.
Quay lại chạy thử chương trình với nonce 0 thì cho kết quả là 9b2963059
Với nonce 1 thì 3dc3bf4a1ed .v.v
Và nếu chúng ta tiếp tục thử với 2, 3, 4 v.v tới nonce 34 sẽ cho chúng ta kết quả hash là 0f13afb6f là 1 cái hash bắt đầu bằng số 0 . Thì các bạn có thể hình dung là sẽ có những con số nonce mà sẽ cho ta có các cái hash bắt đầu bằng một hoặc nhiều số 0 ở đầu.
Rồi thì câu hỏi là Nonce nào sẽ cho chúng ta số hash có nhiều số 0 ở đầu. Thử với target là 5 số 0 ở đầu. Thì phải dùng máy tính để thử tuần tự thôi.
Có tổng cộng maximum là hơn 4.2 tỷ số nonce có khả năng ghép vào block.
Thì cũng không khó để tìm. Một trong những số nonce mà cho chúng ta 5 số 0 ở đầu là: 884965.
Cho chúng ta hash là 0000045d1.
Thì mining đơn giản vậy thôi. Chúng ta sẽ thử viết 1 chương trình để tối ưu hết tất cả sức mạnh của máy tính để thực hiện việc hashing này ha.
Base program#
Đầu tiên để thực hiện thí nghiệm gì thì chúng ta cũng sẽ phải có 1 cái kết quả nền đã.
Ok thì workload chương trình của chúng ta sẽ đơn giản thôi. Hash 1 cái block liên tục sử dụng thuật toán SHA256.
Chúng ta sẽ hash thử trên tập hợp nhỏ nonce là 5 triệu thôi thay vì thử hết 4 tỷ mấy possibility.
Thử hết 4 tỷ nonce đó thì máy Macbook M1 của mình mất tới 22 tiếng lận. nên thôi thí nghiệm với 5 triệu số thôi.
Và chương trình base để lấy kết quả nền này mình gọi là sample_0.rs đi. Nó sẽ thực hiện việc tính toán naive thôi. Chạy loop từ 0 đến 5 triệu và với mỗi số nonce thì thực hiện việc hashing và nếu block bắt đầu bằng 5 số 0 thì in ra.
Chạy thử chương trình. cargo run –example sample_0
Thì kết quả chúng ta mất khoản 95 giây.
Và tìm được 5 cái hash.
Ok thì 95 giây là con số nền ha, chúng ta sẽ cải tiến để chương trình chạy nhanh hơn.
Và các bạn để ý CPU của máy mình trong quá trình chạy không tăng lên quá 25%. Cũng có nghĩa là chúng ta chưa sử dụng được hết tất cả sức mạnh của CPU.
Thì giờ bắt đầu thí nghiệm áp dụng Lập trình Concurrency để sử dụng tối đa tài nguyên của CPU.
Sample_1 Spawn thread#
Ok thì để lập trình Concurrency chúng ta phải sử dụng đến thread. Thì thread là một đơn vị vận hành của chương trình. Các thread có thể chạy độc lập với nhau trong một process và chia sẻ tài nguyên như bộ nhớ memory với nhau.
Với Rust thì thread trong standard library là Native thread có nghĩa là thread được map 1:1 với thread implement bởi hệ điều hành. Khác với go lang là green thread được implement 1 cái lightweight runtime riêng và map 1 với N.
Ngoài thread thì một công cụ nữa cũng quan trọng là channel.
Các bạn có thể hình dung 1 cái channel như dòng suối chảy vậy. Có thể truyền vào ở đầu nguồn một con thuyền giấy nhỏ chứa thông điệp, thì cuối nguồn sẽ có thể nhận được thông điệp đó.
Trong Rust thì tích hợp 1 cái implementation cho channel là mpsc là Multi producer single consumer.
Có nghĩa là chúng ta có thể có 1 channel mà trong đó có nhiều đầu nguồn đi vào nhưng chỉ có thể có 1 nguồn để nhận.
Chương trình đầu tiên chúng ta sẽ áp dụng cách thức sau để xử lý công việc. Chúng ta sẽ có 1 cái main thread là một con Rustatean chính trong hình vẽ này.
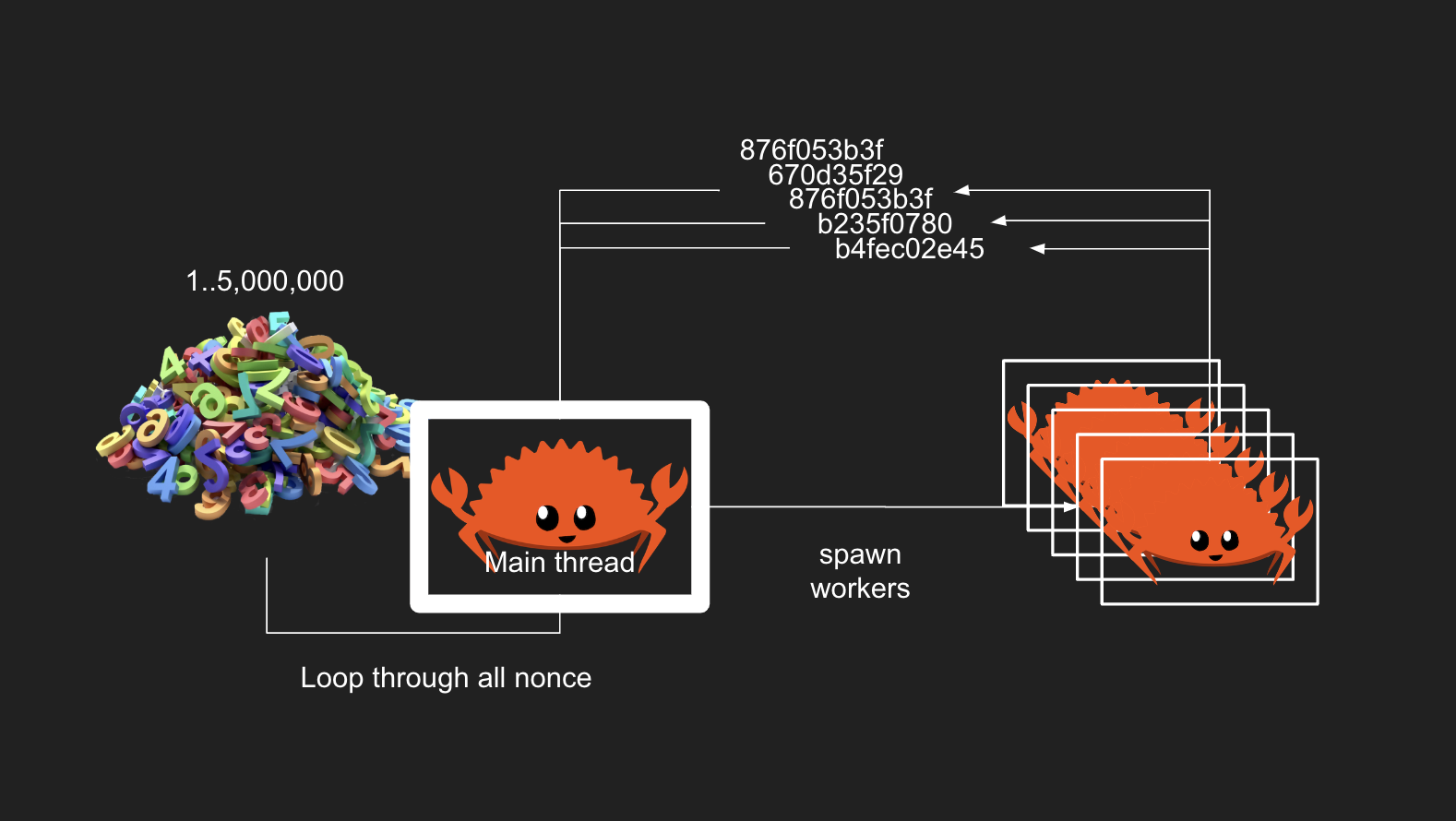
Sẽ loop qua hết tất cả 5 triệu nonce mà chúng ta cần phải tính toán. Và cứ mỗi nonce thì giao nhiệm vụ tính hash của nonce cho worker bằng cách spawn các worker lên.
Và kết quả trả hash về của các worker sẽ được truyền bằng channel về lại cho main thread để nó xử lý việc tìm hash bắt đầu bằng 5 số 0.
Ok thì chúng ta bắt đầu sample_1.rs mình sẽ phát triển dựa trên sample_0.rs thôi. Copy lại code cũ.
Đầu tiên chúng ta sẽ tạo 1 cái channel để truyền và nhận hash. Khai báo bằng mpsc::channel .
Channel này sẽ có type String.
Thì để spawn lên 1 cái thread để handle workload của chương trình. Mình sẽ xử lý ở đây bằng 1 cái closure là spawn_worker ha. Nhận vào argument là nonce: u32.
Sau đó là clone 2 cái thứ vào trong scope này là hash_tx transmitter và nội dung block.
Thì tại sao chúng ta phải clone 2 biến này ở đây. Cũng là một điểm khá hay trong lập trình Rust.
Đây là cơ chế quản lý lifetime của Rust, đưa vào scope bên trong 2 cái biến này dưới dạng clone thay vì sử dụng trực tiếp.
Cơ chế này sẽ giúp Rust quản lý thời gian sử dụng các biến variable của chương trình tới lúc nào trong lúc vận hành. Và biết chính xác lúc thào sẽ drop chúng để giải phóng bộ nhớ memory.
Đó là lý do tại sao Rust không có garbage collector. Là vì tất cả việc quản lý memory này được xử lý kỹ lưỡng ngay trong việc tạo nên chương trình.
Và khi kết hợp cơ chế lifetime này với Borrow Ownership thì Rust đảm bảo được việc sử dụng memory cho toàn bộ chương trình của chúng ta khá là an toàn.
Tránh trường hợp bị memory leak. Hay trong lập trình Concurrency thì tránh trường hợp bị data race.
Để spawn lên thread mới chúng ta sử dụng hàm thread::spawn. Tính ra hash của block. Khi làm việc xong có kết quả thì worker trả kết quả về bằng channel.
Trong main thread thì chúng ta loop qua tất cả các số nonce và dùng hàm helper print_progress này để in ra tiến độ thực hiện của chương trình mỗi 10%. Xem nhanh qua hàm này thì không có gì đặc biệt, nếu số nonce chia hết cho 1 phần 10 của max - max chia 10 nè. Thì in tiến độ ra thôi.
Quay lại main. Thì mình sẽ buffer lên 1 lượng Worker để tính hash. Sử dụng hàm spawn_worker ở trên. Bên trong cái if nonce nhỏ hơn THREAD_AMOUNT này thì sẽ chỉ chạy với các worker đầu tiên để buffer sau đó continue để loop tiếp nonce tiếp theo.
Sau khi spawn được 1 lượng worker buffer nhất định dựa trên hằn số THREAD_AMOUNT này thì chúng ta mới bắt đầu xử lý tiêp việc nhận của channel.
Thì để nhận kết quả của các worker, chúng ta sẽ dùng hàm receive viết tắt là recv(). Dùng match expression để xử lý Lỗi Error. Rồi nếu OK thì kiểm tra nếu nonce bắt đầu bằng 5 số 0 thì println ra output.
Cuối cùng thì chúng ta sẽ spawn worker mới để tiếp tục loop đến hết cái kho nonce kia.
Và cuối cùng cũng giống như sample_0 chúng ta sẽ println ra thời gian mà chương trình xử lý.
Ok thì chúng ta thử chạy chương trình này. cargo run –example sample_1
Và kết quả cuối cùng là 56 57 giây.
Rút ngắn được khoản 38 giây. tức giảm được 40% thời gian xử lý.
Một kết quả khả quan hơn chương trình trước rất nhiều. Nhưng vẫn chưa phải là kết quả tối ưu. Ở đây mình cố ý tạo ra một bottleneck để demo cái chưa tối ưu của cách thức này.
Để ý là trong lúc chạy chương trình này thì CPU của máy chưa chạy đến hết được sức mạnh mà chỉ dừng ở khoản 50 mấy 60%.
Tức là ở đâu đó các thread vẫn phải chờ nhau để vận hành.
Rồi chúng ta sẽ thử cải tiến chương trình ở sample tiếp theo ha.
Sample_2 Sync with Arc-Mutex#
Thì với lập trình concurrency việc phát hiện ra các bottleneck khá là quan trọng. Nếu chương trình của chúng ta không tối ưu được các tài nguyên của hệ thống thì việc sử dụng sẽ kém hiệu quả.
Trong chương trình vừa rồi ở sample_1 chúng ta bị vướng 1 chỗ thắt cổ chai là main thread. Mainthread nó phải xử lý việc điều phối kho số nonce cho các worker thread.
Điều này làm cho hệ thống của chúng ta bị phụ thuộc vào tốc độ phân phối công việc của main thread. Nếu main thread bị chậm hơn so với tốc độ xử lý của các worker thread thì chúng phải chờ.
Các bạn có thể tưởng tượng là có anh giám đốc phải phân công việc chi ly từng tí cho các nhân viên. Thì tập thể này sẽ bị chậm nếu anh giám đốc không phân việc kiệp.
Thì chúng ta sẽ cải tiến hệ thống ở sample_1 như thế nào để main thread không còn là bottleneck?
Giải pháp là trước khi nhào vô xử lý tác vụ. Chúng ta sẽ chia khối lượng công việc ra thành các chunks. Có nghĩa là chia ra thành các khúc nhỏ hơn. Và mỗi worker sẽ xử lý 1 chunk.
Ví dụ chúng ta có 5 triệu số nonce thì có thể chia ra cho 5 workers mỗi worker xử lý 1 triệu số như vầy. Khi nhận được nhiệm vụ thì tự các worker sẽ lấy từng con số nonce mà tính ra các hash. Không phụ thuộc vào main thread nữa tăng tính chạy độc lập cho từng worker thread.
Quay lại hình ảnh anh giám đốc, thì hệ thống này các bạn có thể hình dung là anh chia công việc ra thành những nhóm công việc nhỏ hơn và phân công cho các anh quản lý tự xử lý việc chứ không quản lý kiểu chi ly nữa.
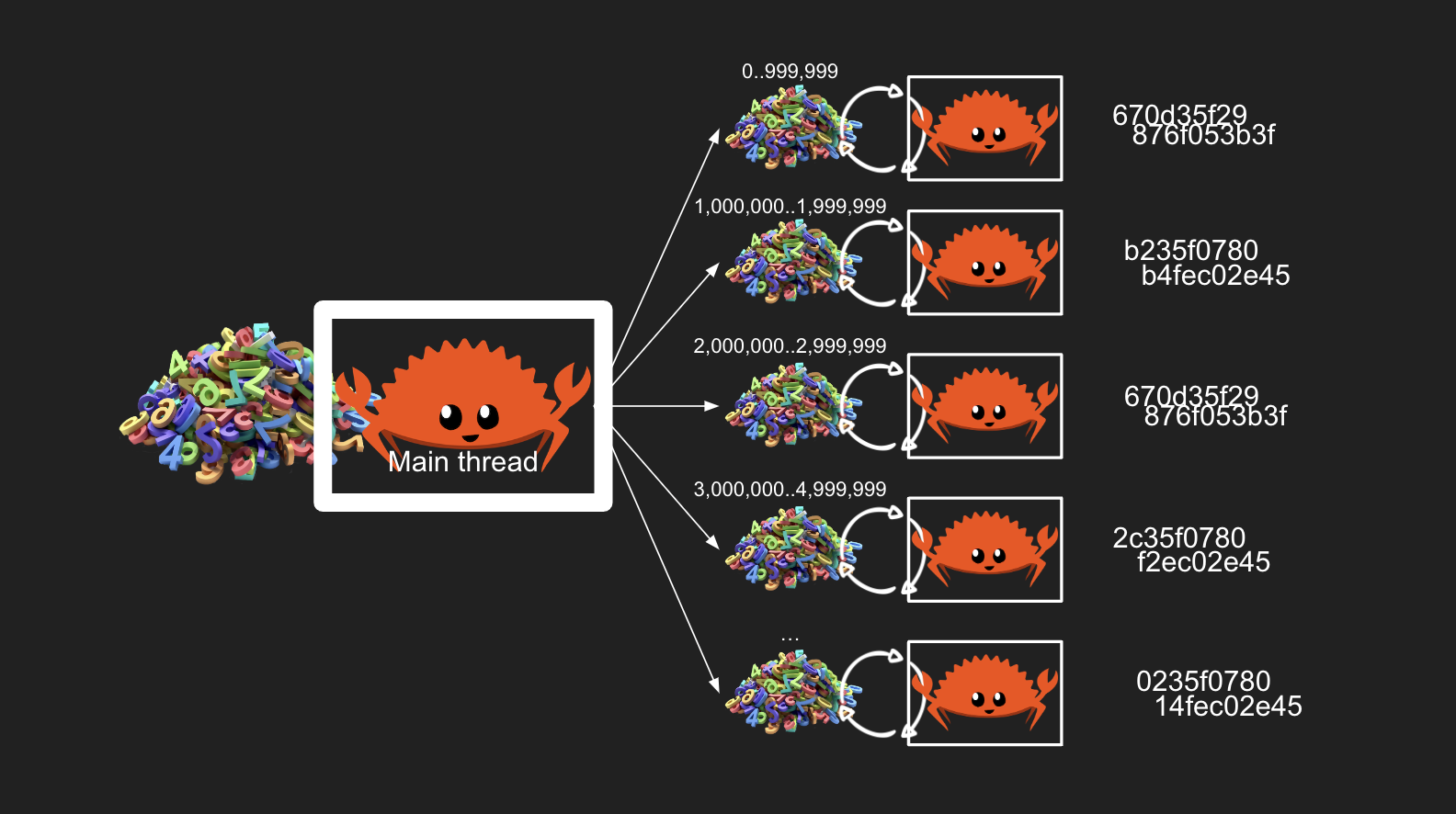
Thì để áp dụng mô hình làm việc mới này. Mình sẽ tạo ra 1 sample mới là sample_2.rs.
Trong này sẽ áp dụng 1 công vụ dùng trong lập trình concurrency nữa của Rust là Arc-Mutex. Thay cho công cụ Channel như sample_1.rs
Thì Arc-Mutex là một cái biến mà chúng ta có thể dùng để trao đổi qua lại giữa các thread bằng cách sử dụng cơ chế locking.
Mutex là Mutual Exclusion, tạm dịch là cơ chế Loại trừ lẫn nhau, cho phép chỉ có 1 thread có thể truy cập vào biến ở 1 thời điểm. Các thread khác phải chờ để đến lượt.
Thì cơ chế này khá nguy hiểm và bất tiện hơn cơ chế dòng nước channel. Do phải nhớ việc locking và unlocking khi sử dụng. Nhưng điều này không quá khó với Rust nhờ vào hệ thống ownership của Rust rất chặt chẽ nên việc sử dụng Mutex rất dễ dàng khi dùng trong lập trình Rust.
ARC hay đọc là Arc là viết tắt của Atomic Reference Counter, là công cụ để chia sẽ các con trỏ reference đến 1 biến.
Thì ở đây mình sẽ bọc Mutex trong Arc để chia sẽ biến này giữa các con thread workers. Gọi biến này là nonce_counter. Biến này sẽ dùng để đếm số lượng nonce đã được xử lý.
Tiếp theo là hàm spawn_worker chúng ta sẽ chỉnh lại không nhận vào chỉ 1 nonce nữa mà nhận vào 1 vector nonces. Đây sẽ là tập hợp các số nonce được giao cho worker này.
Sau đó cũng như sample_1 chúng ta cần clone các biến vào trong scope của worker. Clone block vào và clone nonce_count vào.
Và spawn lên 1 cái thread thôi.
Và mỗi thread sẽ có 1 cái for loop để xử lý hết tất cả các nonce được giao. Chạy qua từng nonce và tính ra chuỗi hash. Và nếu hash bắt đầu bằng 5 số 0 thì in ra, cũng như sample_1 thôi.
Cuối cùng khi hoàn tất 1 nonce chúng ta sẽ báo cáo số lượng nonce_count bằng Arc-Mutex. Bằng cách là request lock cái Arc để các thread khác không đụng đến biến này. Và thực hiện việc cộng 1 cho cái số được reference bên trong là cục Mutex, mình đặt tên ở đây là nonce_count_inner.
Bằng cách này nonce_count sẽ được cộng 1 atomically không sợ bị race condition giữa các thread.
Ok thì để xem tiến độ thực hiện mình cũng sử dụng print_progress để in ra tiến độ của chương trình trong lúc chạy ở đây luôn.
Rồi thì chuẩn bị cho spawn_worker xong. Để chạy chương trình thì phân cái kho 5 triệu nonce ra thành những chunks nhỏ. Chia ra tuỳ theo số lượng thread mà chúng ta sẽ tiến hành, số lượng mình config trong cái hằng số THREAD_AMOUNT này như cũ.
Và với mỗi chunk thì chúng ta sẽ giao nhiệm vụ cho các con worker để chạy và xử lý.
Cuối cùng thì join các worker thread với main thread để chương trình kết thúc sạch sẽ. Và print ra thời gian thực hiện.
Ok thì bây giờ chúng ta thử chạy chương trình. cargo run –example sample_2
Và kết quả là chương trình chỉ mất hơn 20 giây để chạy.
Nhanh hơn sample_1 nhiều. Giảm chỉ còn ⅓ lần sample_1 lúc nãy chạy mất gần 60 giây.
Còn so với sample_0 là kết quả nền thì chúng ta giảm từ 90 giây xuống còn 20 giây thôi là giảm được hơn 4 lần thời gian.
Và các bạn cũng để ý chúng ta tối ưu được hết tất cả CPU chạy 100%.
Conclusion#
Ok thì qua video này mình demo được kỹ năng về lập trình Concurrency. Thử nghiệm một vài công cụ lập trình Concurrency căn bản của Rust.
Về kỹ năng này thì như các bạn cũng biết công nghệ CPU bây giờ không còn đi theo hướng đua tốc độ Gigaherzt nữa mà chuyển sang tối ưu hoá việc xử lý đa luồng.
Xử lý càng nhiều tác vụ cùng lúc càng tốt. Thì chương trình chúng ta thiết kế cũng vậy, cũng sẽ phải đi theo hướng này để tối ưu hoá các tài nguyên trong lúc vận hành.
Và không những chương trình máy tính mà cách thức thiết kế hệ thống cũng vậy. Hầu hết đang hướng sang hướng phi tập trung.
Mình cũng rất thích thú đào sâu thêm về các chương trình dạng này. Và trải nghiệm nó qua ngôn ngữ Rust mới hiểu được tại sao Rust được xem là ngôn ngữ được ưa thích.
Cách sử dụng nó với lập trình concurrency trực quan hơn và an toàn hơn các ngôn ngữ khác nhiều.
Anyway sắp tới mình sẽ áp dụng Rust vào một vài dự án khá thú vị. Trong đó sẽ dùng một số công cụ mới được phát triển gần đây tận dụng lợi thế của Rust. Một trong những công cụ đó là Surreal Db. Sẽ chia sẻ trải nghiệm này qua những Video sau ha.
Cảm ơn các bạn đã theo dõi tới đây. Xin chào và hẹn gặp lại. Chop out!